
用ChatGPT写文献综述相关代码(知网篇)
公众号:三分甜的涠
文章链接:用ChatGPT写文献综述相关代码(知网篇)
爬取知网相关主题文献
通过 Python 获取文章的基本信息和详情页链接,再通过详情页链接来获取文章的摘要。
- 下面的代码只需要更改搜索主题、保存路径即可。
- 可设置一个或多个关键词

- 设置爬取页数
- 运行过程

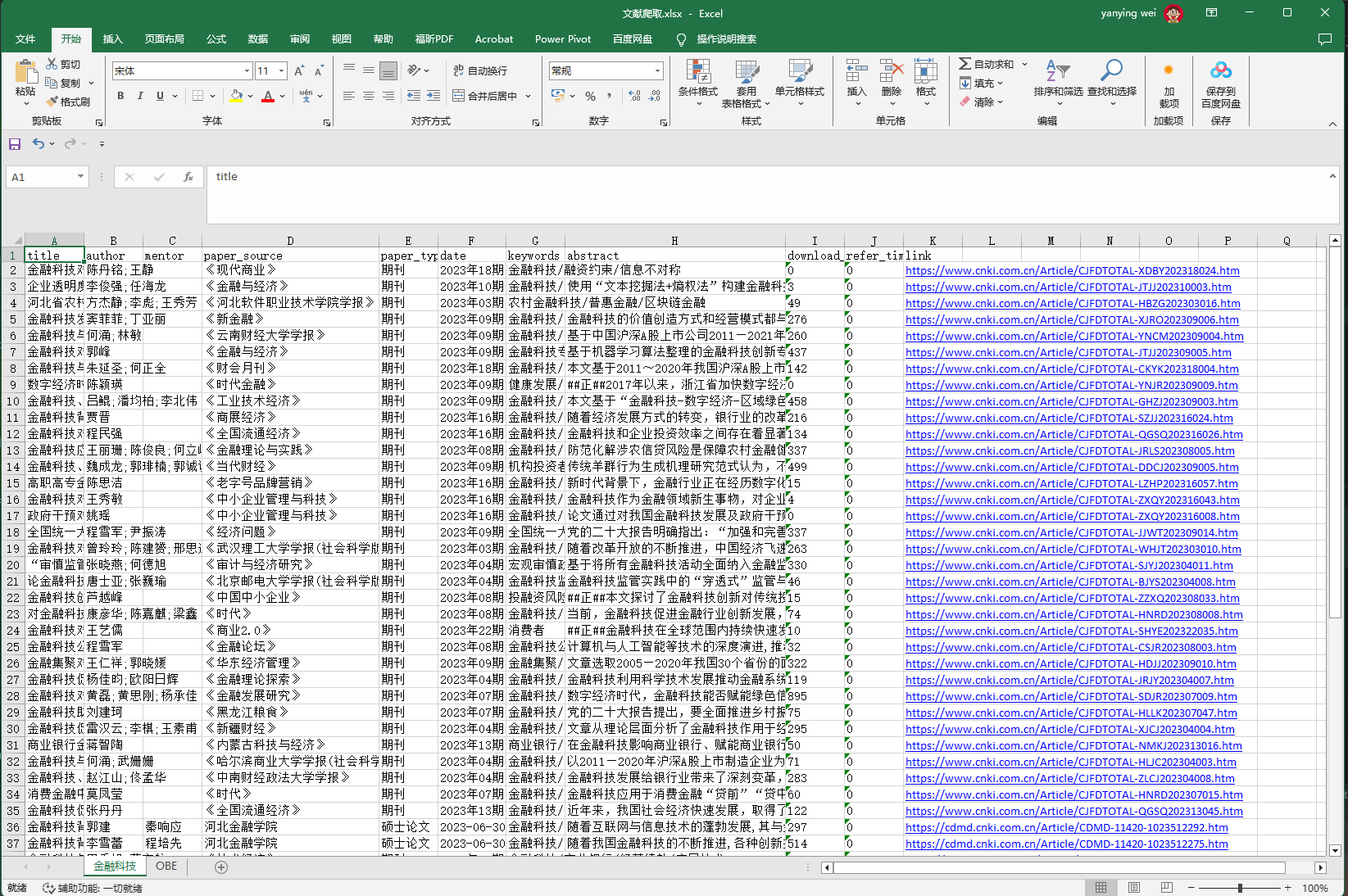
- 爬取结果
文献评分
由于每次可以输入的内容有限,ChatGPT 和 GPT-4 的记忆也都是有限的,因此直接把多篇文章都传上去会相当困难,设计一套算法筛选出有价值的文章是高效而便捷的方式。
假设评分公式为:
总评分=被引频次*0.3+下载频次*0.7+附加分
- 读取文件
- 计算分数

- 保存到excel文件

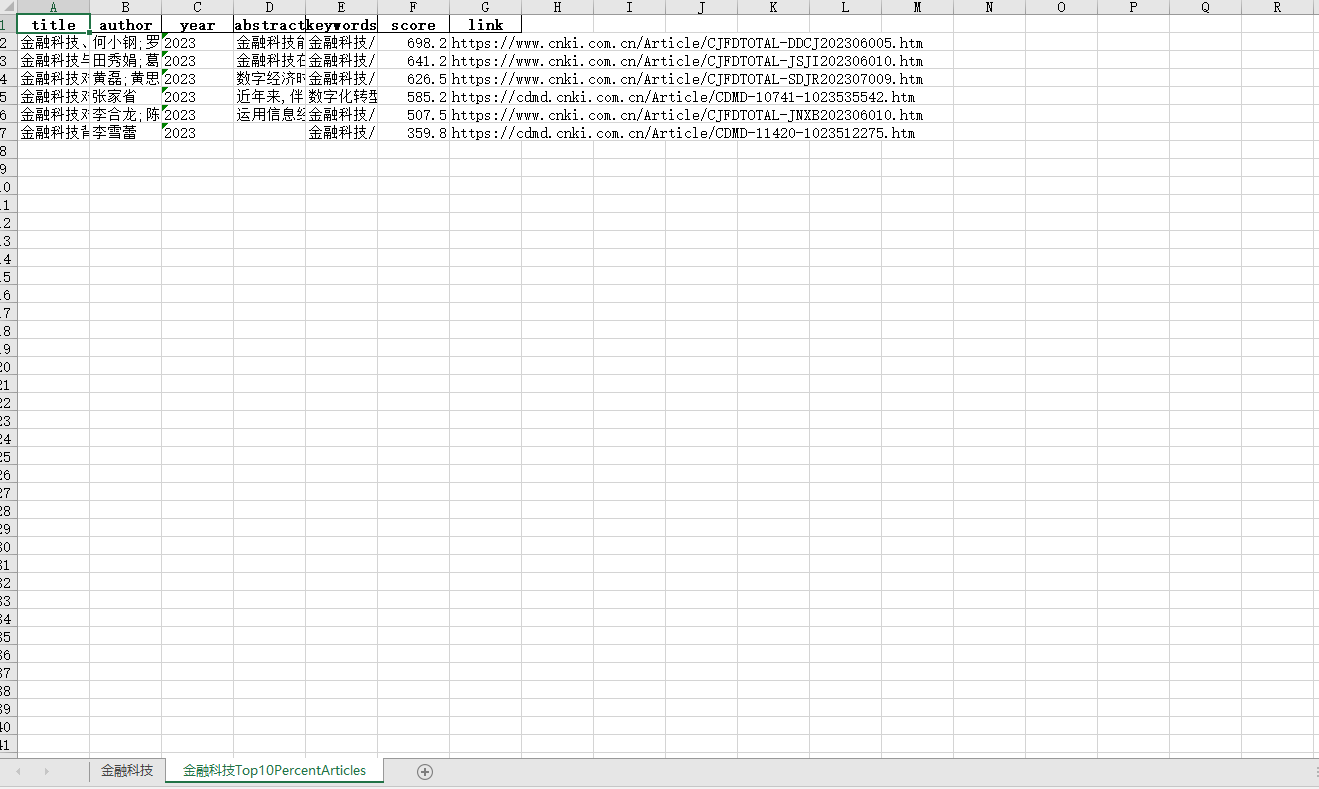
合并优质论文
- 读取文件,需要更改路径和文件名
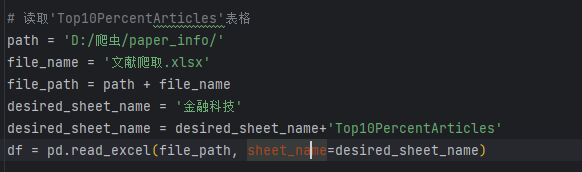
- 保存成txt文档

提问ChatGPT
作为一位金融科技领域的专家,您了解该领域所有的前沿知识、专业名词、模型方法、算法技术等必备的知识,同时具有较好的文献阅读能力和信息总结能力。

我即将给您发送论文信息。第一部分是作者,第二部分是发表时间,第三部分是文章的标题,第四部分是研究结论。
在你生成的内容中一定要注明引用的文献,标注的方式为(作者,时间)。请先综合所有的论文的研究结论,把这些研究结论按照研究方面的不同进行分类。如果你明白我的意思,请回复明白,请你提供文献。
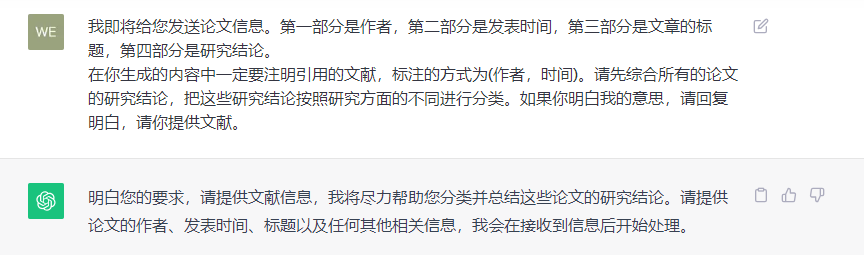
何小钢;罗欣;郭晓斌 2023 金融科技、资源配置与银行业结构 金融科技能否促进传统银行业有效竞争,对于金融业更好地服务实体经济具有重要意义。利用2011—2020年290个城市数据的实证研究表明,金融科技通过竞争效应和赋能效应导致网点退出市场,同时抑制网点进入。从银行异质性来看,金融科技的资源配置效应让大型商业银行网点退出规模更大,而金融科技的技术赋能效应则让上市银行网点退出规模更大。从城际异质性来看,经济发展状况较好、人口老龄化较低、教育水平较强以及贷存比较低的城市,网点受到金融科技冲击更大,网点退出更显著。从影响渠道来看,金融科技减少了家庭的银行储蓄,优化了家庭资产配置,引致低效网点退出。进一步的研究发现,金融科技通过影响银行网点的进入退出行为,降低了银行市场集中度,优化了金融业竞争格局。同时,金融科技还弥补了网点退出对地区金融贷款造成的不利影响。
田秀娟;葛宇航 2023 金融科技与商业银行经营绩效 金融科技在创新业务、流程和产品的同时带来了利差的收窄,然而对商业银行经营绩效的影响尚未得到一致结论。本文使用文本挖掘法构建了我国135家商业银行金融科技发展水平指标,基于2012—2019年数据,实证检验了金融科技与商业银行经营绩效的关系。结果表明,样本期内银行内部金融科技对小银行经营绩效没有影响;剔除小银行后,金融科技对经营绩效的影响呈先降后升的“U”形关系。具体而言,底层金融科技对商业银行经营绩效无显著影响,应用金融科技对经营绩效的影响呈“U”形。地区金融科技的发展会降低商业银行的经营绩效。机制分析表明金融科技可以通过影响商业银行的成本管理、风险控制和经营效率三条路径影响商业银行的经营绩效。
黄磊;黄思刚;杨承佳 2023 金融科技对绿色信贷的影响及作用机制——基于商业银行金融科技视角 数字经济时代,金融科技能否赋能绿色信贷发展,从而推动商业银行实现数字化绿色转型?本文创新性地从商业银行内部视角出发,基于2012—2021年22家中国上市商业银行数据,利用文本挖掘法构建金融科技发展指数,探究金融科技对绿色信贷的影响。研究发现,金融科技通过缓解信息不对称、调整信贷配置和降低信贷风险显著促进了绿色信贷的投放。异质性分析表明,金融科技对绿色信贷投放的促进作用在规模小、资本充足率高的商业银行以及城市商业银行中表现得更加明显。因此,商业银行应持续推进金融科技发展,以助力我国绿色金融的发展以及“双碳”目标的实现。
张家省 2023 金融科技对商业银行数字化转型的影响研究 近年来,伴随着互联网技术的日益普及,金融科技的飞速发展,金融业既面临着严峻的挑战,又面临着前所未有的发展机会。随着金融技术的迅速发展,传统的融资方式得到了很大的改进。数字化转型是我国商业银行发展的必然趋势,是提高我国商业银行整体业务水平和获取竞争优势的关键所在。文章从商业银行管理和业务两个不同的视角,通过对国内外有关文献的汇总整理,明确了金融科技与银行数字化转型的含义和发展进程,并对我国金融科技和数字化转型的发展现状以及应用领域进行了描述;以金融创新理论、长尾和技术推进理论为理论依据,基于银行管理水平和业务水平的调节作用下,深度剖析了商业银行利用金融科技对其数字化转型的总效用。利用文本挖掘法对金融科技指数、数字化转型指数进行测算,选取20家上市银行为研究样本展开实证检验,对不同类型的商业银行所产生的影响进行异质性分析,进而得出相应的结论与建议。本文得出的主要结论是基于银行管理水平的调节作用下,金融科技对商业银行数字化转型的总效应更为显著;虽然银行业务水平在数字化转型过程中起到了弱化的作用,但是并不影响金融科技推进数字化转型的进程。金融科技对商业银行数字化转型的作用效果存在异质性,相比于城商和农商行,国有行和股份制商业银行的作用效果更加明显。
李合龙;陈孝明 2023 金融科技对粤港澳大湾区科技创新的影响研究 运用信息经济学相关理论分析金融科技对粤港澳大湾区科技创新的影响机理和路径,基于2014—2021年的数据,实证检验金融科技的发展对大湾区科技创新的推动作用。研究发现:金融科技对大湾区科技创新具有显著的正向促进作用。金融科技能够通过缓解融资约束和激发市场潜能两条路径,促进粤港澳大湾区的科技创新。异质性分析表明,在经济发展水平比较低的城市,金融科技对科技创新的促进作用更加显著。提出了加强粤港澳大湾区城市间金融科技发展、强化要素流动激发市场潜能等粤港澳大湾区金融科技支持科技创新的政策建议。研究结论对金融科技如何促进粤港澳大湾区科技创新发展、更好发挥服务实体经济的功能具有重要意义。
李雪蕾 2023 金融科技背景下招商银行中间业务转型案例分析 nan
根据您提供的论文信息,我将按照研究方向对这些论文的研究结论进行分类总结:
1. 金融科技与银行业结构
金融科技通过竞争效应和赋能效应影响银行网点的进入和退出行为,降低银行市场集中度,优化金融业竞争格局,并补偿了网点退出对地区金融贷款的不利影响 (何小钢, 罗欣, 郭晓斌, 2023)。
2. 金融科技与商业银行经营绩效
金融科技对商业银行的经营绩效影响呈“U”形关系,对小银行影响较小,但对底层金融科技和应用金融科技有显著影响。地区金融科技的发展降低商业银行的经营绩效,通过影响成本管理、风险控制和经营效率三个路径影响商业银行的经营绩效 (田秀娟, 葛宇航, 2023)。
3. 金融科技与绿色信贷
金融科技通过缓解信息不对称、调整信贷配置和降低信贷风险,促进了绿色信贷的投放。对于规模小、资本充足率高的商业银行和城市商业银行,金融科技对绿色信贷的促进作用更加明显 (黄磊, 黄思刚, 杨承佳, 2023)。
4. 金融科技与商业银行数字化转型
金融科技对商业银行的数字化转型产生积极影响。金融科技在提高商业银行整体业务水平和获取竞争优势方面具有关键作用。根据文献研究,金融科技对商业银行数字化转型的总效应更为显著,尤其在国有行和股份制商业银行中 (张家省, 2023)。
5. 金融科技与科技创新
金融科技对粤港澳大湾区科技创新有显著的正向促进作用,通过缓解融资约束和激发市场潜能促进科技创新。尤其在经济发展水平较低的城市,金融科技对科技创新的促进作用更加明显 (李合龙, 陈孝明, 2023)。
以上是根据您提供的论文信息总结的研究结论,每个论文都涉及不同的方面和影响因素,从银行业结构到经营绩效、绿色信贷、数字化转型以及科技创新。这些研究为理解金融科技在不同领域中的影响提供了重要见解。如果您需要更详细或特定方面的信息,请随时提出具体问题。


代码如下:
论文爬取
import requests
from lxml import etree
import os
import time
import xlsxwriter as xw
import re
base_url = 'http://search.cnki.com.cn/Search/ListResult'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0',
# 'Content-Type': 'application/x-www-form-urlencoded',
# 'Content-Length': '463'
}
def get_page_text(url, headers, search_word, page_num):
data = {
'searchType': ' MulityTermsSearch',
'ArticleType': '',
'ReSearch': '',
'ParamIsNullOrEmpty': ' false',
'Islegal': ' false',
'Content': search_word,
'Theme': '',
'Title': '',
'KeyWd': '',
'Author': '',
'SearchFund': '',
'Originate': '',
'Summary': '',
'PublishTimeBegin': '',
'PublishTimeEnd': '',
'MapNumber': '',
'Name': '',
'Issn': '',
'Cn': '',
'Unit': '',
'Public': '',
'Boss': '',
'FirstBoss': '',
'Catalog': '',
'Reference': '',
'Speciality': '',
'Type': '',
'Subject': '',
'SpecialityCode': '',
'UnitCode': '',
'Year': '',
'AuthorFilter': '',
'BossCode': '',
'Fund': '',
'Level': '',
'Elite': '',
'Organization': '',
'Order': ' 1',
'Page': str(page_num),
'PageIndex': '',
'ExcludeField': '',
'ZtCode': '',
'Smarts': '',
}
response = requests.post(url=url, headers=headers, data=data)
page_text = response.text
return page_text
def get_abstract(url):
response = requests.get(url=url, headers=headers)
page_text = response.text
tree = etree.HTML(page_text)
# 使用新提供的XPath定位摘要所在的元素
abstract_elements = tree.xpath('//*[@id="content"]/div[2]/div[4]/text()')
# 将摘要元素连接成一个字符串
abstract = ''.join(abstract_elements).strip()
# # 去除【摘要】和【作者单位】
# abstract = abstract.replace('【摘要】:', '').split('【作者单位】:')[0].split('【学位授予单位】:')[0].split('【学位级别】:')[0].split('【学位授予年份】:')[0]
# 去除多余空格和换行符
abstract = abstract.strip()
# # 去除冒号
# abstract = abstract.rstrip(':')
# 去除CR字符
abstract = abstract.replace('_x000D_', '')
return abstract
def list_to_str(my_list):
my_str = "".join(my_list)
return my_str
def parse_page_text(page_text):
tree = etree.HTML(page_text)
item_list = tree.xpath('//div[@class="list-item"]')
page_info = []
for item in item_list:
# 标题
title = list_to_str(item.xpath(
'./p[@class="tit clearfix"]/a[@class="left"]/@title'))
# 链接
link = 'https:' +\
list_to_str(item.xpath(
'./p[@class="tit clearfix"]/a[@class="left"]/@href'))
# 作者
author = list_to_str(item.xpath(
'./p[@class="source"]/span[1]/@title'))
# 导师
mentor = list_to_str(item.xpath(
'./p[@class="source"]/span[2]/a[1]/text()'))
# 出版日期
date = list_to_str(item.xpath(
'./p[@class="source"]/span[last()-1]/text() | ./p[@class="source"]/a[2]/span[1]/text() '))
# 关键词
keywords = list_to_str(item.xpath(
'./div[@class="info"]/p[@class="info_left left"]/a[1]/@data-key'))
# 摘要
abstract = list_to_str(get_abstract(url=link))
# 文献来源
paper_source = list_to_str(item.xpath(
'./p[@class="source"]/span[last()-2]/text() | ./p[@class="source"]/a[1]/span[1]/text() '))
# 文献类型
paper_type = list_to_str(item.xpath(
'./p[@class="source"]/span[last()]/text()'))
# 下载量
download_times_element = item.xpath('./div[@class="info"]/p[@class="info_right right"]/span[@class="time1"]')[0]
download_times = re.search(r'((\d+))', download_times_element.text).group(
1) if download_times_element.text else '0'
# 被引量
refer_times_element = item.xpath('./div[@class="info"]/p[@class="info_right right"]/span[@class="time2"]')[0]
refer_times = re.search(r'((\d+))', refer_times_element.text).group(1) if refer_times_element.text else '0'
item_info = [i.strip() for i in [title, author, mentor,
paper_source, paper_type, date, keywords, abstract, download_times, refer_times, link]]
page_info.append(item_info)
# print(page_info)
return page_info
def write_to_excel(workbook, info, search_word):
wb = workbook
worksheet1 = wb.add_worksheet(search_word) # 创建子表
worksheet1.activate() # 激活表
title = ['title', 'author', 'mentor',
'paper_source', 'paper_type', 'date', 'keywords', 'abstract', 'download_times', 'refer_times', 'link'] # 设置表头
worksheet1.write_row('A1', title) # 从A1单元格开始写入表头
i = 2 # 从第二行开始写入数据
for j in range(len(info)):
insert_data = info[j]
start_pos = 'A' + str(i)
# print(insert_data)
worksheet1.write_row(start_pos, insert_data)
i += 1
return True
if __name__ == '__main__':
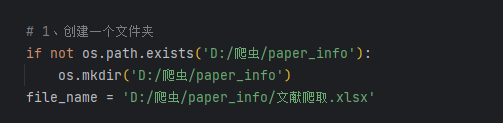
# 1、创建一个文件夹
if not os.path.exists('D:/爬虫/paper_info'):
os.mkdir('D:/爬虫/paper_info')
file_name = 'D:/爬虫/paper_info/文献爬取.xlsx'
# 2、设置搜索词
search_words = ['金融科技']#[ '数字技术', '数字应用', '互联网商业模式', '现代信息系统']
# 3、创建工作簿
workbook = xw.Workbook(filename=file_name)
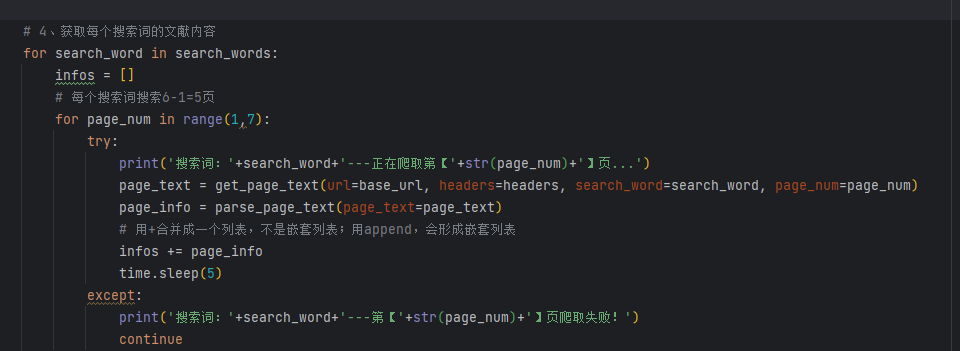
# 4、获取每个搜索词的文献内容
for search_word in search_words:
infos = []
# 每个搜索词搜索6-1=5页
for page_num in range(1,7):
try:
print('搜索词:'+search_word+'---正在爬取第【'+str(page_num)+'】页...')
page_text = get_page_text(url=base_url, headers=headers, search_word=search_word, page_num=page_num)
page_info = parse_page_text(page_text=page_text)
# 用+合并成一个列表,不是嵌套列表;用append,会形成嵌套列表
infos += page_info
time.sleep(5)
except:
print('搜索词:'+search_word+'---第【'+str(page_num)+'】页爬取失败!')
continue
# 5、按照搜索词,依次写入工作簿
write_to_excel(workbook, infos, search_word)
# 6、关闭工作簿
workbook.close()
print(f'爬取完成!{file_name}')
文献评分
import pandas as pd
# 读取Excel文件
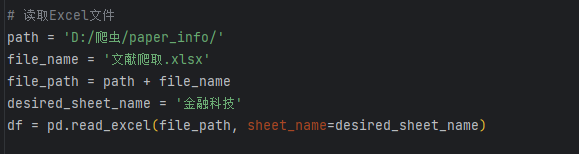
path = 'D:/爬虫/paper_info/'
file_name = '文献爬取.xlsx'
file_path = path + file_name
desired_sheet_name = '金融科技'
df = pd.read_excel(file_path, sheet_name=desired_sheet_name)
# 提取年份(假设年份信息在'date'列的前4位)
df['year'] = df['date'].str[:4]
# 计算分数
df['score'] = 0.3 * df['refer_times'] + 0.7 * df['download_times']
# 按年份分组并筛选每年排名前10%的文章
result = df.groupby('year').apply(lambda x: x.nlargest(int(0.1 * len(x)), 'score')).reset_index(drop=True)
# 选择输出的列
result = result[['title', 'author', 'year', 'abstract', 'keywords','score','link']]
# 创建一个新的ExcelWriter以保存结果
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a') as writer:
try:
writer.book.remove(writer.sheets[desired_sheet_name+'Top10PercentArticles'])
except KeyError:
pass # 工作表不存在,无需删除
result.to_excel(writer, sheet_name=desired_sheet_name+'Top10PercentArticles', index=False)
print(f'处理完成并保存结果到{file_path}的Excel文件中。表名: {desired_sheet_name}Top10PercentArticles')
合并优质文献
import pandas as pd
import os
# 读取'Top10PercentArticles'表格
path = 'D:/爬虫/paper_info/'
file_name = '文献爬取.xlsx'
file_path = path + file_name
desired_sheet_name = '金融科技'
desired_sheet_name = desired_sheet_name+'Top10PercentArticles'
df = pd.read_excel(file_path, sheet_name=desired_sheet_name)
# 合并每一行的数据
merged_data = df.apply(lambda row: f"{row['author']} {row['year']} {row['title']} {row['abstract']}", axis=1)
# 将合并后的数据写入txt文件
output_file = 'D:/爬虫/paper_info/merged_data.txt'
with open(output_file, 'w', encoding='utf-8') as file:
file.write('\n'.join(merged_data))
print(f'数据已成功写入txt文件。{output_file}')